News
[09/2025] Two papers accepted to NeurIPS 2025 (PhysX-3D as Spotlight presentation).
[08/2025] CityDreamer4D is accepted to IEEE TPAMI.
[08/2025] OnePoseViaGen accepted to CoRL 2025 as Oral presentation.
[06/2025] Three papers accepted to ICCV 2025 (Free4D, DCM, and TACA).
[06/2025] We are organizing CVPR 2025 Tutorial on From Video Generation to World Models.
[06/2025] Selected for CVPR 2025 Doctoral Consortium!
[04/2025] Recognized as China3DV 2025 Rising Star Honorable Mention Award!
[04/2025] Invited Talk at Oxford VGG on "Feedforward Primitive-based 3D Generation".
[03/2025] Oral presentation at 3DV 2025 Nectar Track Spotlights for LGM and 3DTopia-XL.
[02/2025] Awarded Meshy PhD Fellowship 2025!
[02/2025] Two papers accepted to CVPR 2025 (3DTopia-XL as Highlight and GaussianCity).
[01/2025] Invited Talk at AIR Tsinghua on "Towards General Neural 3D Asset Generation".
[11/2024] Guest Lecture at University of Michigan.
[10/2024] Invited Talk at WiseModel on "Native 3D Generative Models".
[08/2024] Invited Talk at Stanford SVL on "From 3D Generative Models to Dynamic Embodied Learning".
[07/2024] Invited Talk at GAMES Webinar on "Unbounded 3D Scene Generation".
[07/2024] One paper accepted to ECCV 2024 as Oral presentation.
[04/2024] One paper accepted to IEEE TPAMI.
[03/2024] Two papers accepted to CVPR 2024 with URHand as Oral presentation.
[01/2024] Invited Talk at ReadPaper on Primitive Diffusion.
[01/2024] One paper accepted to IJCV.
[09/2023] One paper accepted to NeurIPS 2023.
[09/2023] Invited Talk at DeepBlue AI on Unbounded 3D Scene Generation.
[09/2023] One paper accepted to IEEE TPAMI.
[07/2023] Two papers accepted to ICCV 2023.
[04/2023] Selected as 2023 Meta Research PhD Fellowship Finalist!
[02/2023] One paper accepted to CVPR 2023 as Highlight.
[01/2023] One paper accepted to ICLR 2023 as Spotlight.
[08/2022] One paper accepted to TOG (Proc. SIGGRAPH Asia 2022).
[07/2022] One paper accepted to ECCV 2022.
[08/2021] Join MMLab@NTU!
[05/2021] Awarded AISG PhD Fellowship!
[07/2021] One paper accepted to ICCV 2021 for Oral presentation.
Awards



2025


2023
Meta Research PhD Fellowship, Finalist

2023
PREMIA Best Student Paper, Honorable Mention

2021
Publications
Neural Rendering & Generative Models
* denotes equal contributions























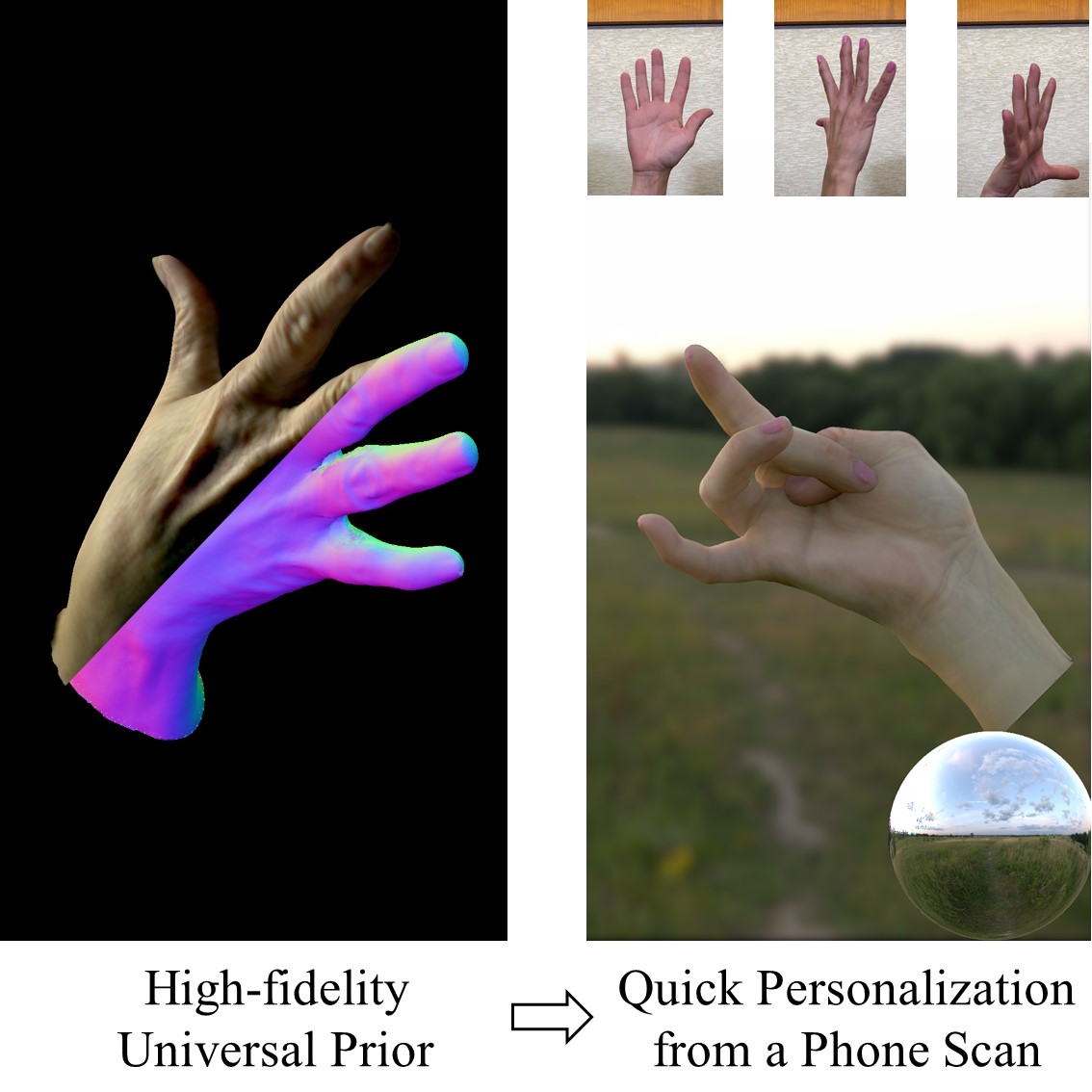


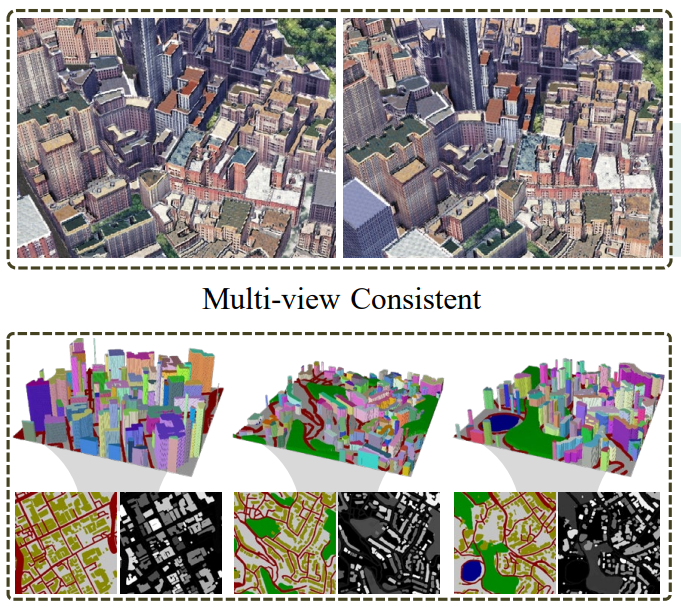


















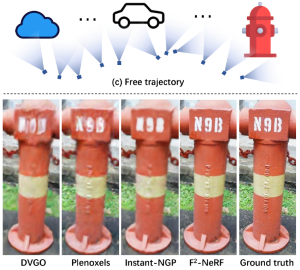














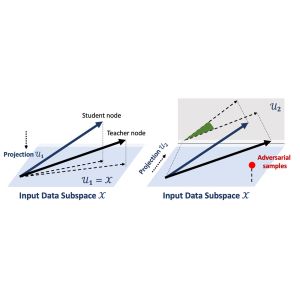
Experiences


Jun. 2023 - Sep. 2023
Reality Labs, Meta
Research Scientist Intern worked with Shunsuke Saito

May. 2020 - Oct. 2020
Secure Learning Lab, UIUC
Visiting Research Intern advised by Prof. Bo Li

Services
Conference Reviewer
- CVPR 2023, 2024, 2025
- ICCV 2023, 2025
- SIGGRAPH 2023, 2024
- SIGGRAPH Asia 2024
- NeurIPS 2023, 2024
- ICLR 2024, 2025
- ICML 2024, 2025
- ECCV 2024
Journal Reviewer
- TOG
- IJCV
- TVCG
- Neurocomputing
- CGA